DSpark 的 661% 提速,是真突破还是数字游戏?
Site Owner
Published on 2026-07-01
DSpark 的 661% 提速,是真突破还是数字游戏? 2026 年 6 月 27 日,DeepSeek 和北大联合放出论文《DSpark》,梁文锋亲自署名。隔天,爱范儿、量子位接连拆解,标题里都写着两个数字:单用户生成速度提升 85%,高并发场景系统吞吐名义优势 661%。 85% 看起来还行。661% 这个数字太像营销话术了——你买股票一年能涨 661% 吗?一家公司能让推理速度凭空翻 6 ...
DSpark 的 661% 提速,是真突破还是数字游戏?
2026 年 6 月 27 日,DeepSeek 和北大联合放出论文《DSpark》,梁文锋亲自署名。隔天,爱范儿、量子位接连拆解,标题里都写着两个数字:单用户生成速度提升 85%,高并发场景系统吞吐名义优势 661%。
85% 看起来还行。661% 这个数字太像营销话术了——你买股票一年能涨 661% 吗?一家公司能让推理速度凭空翻 6 倍?
这篇论文到底在说什么?这 661% 是怎么算出来的?以及更重要的:DeepSeek 把这套东西开源,意味着大模型竞争进入了什么新阶段?
答案分三层:这是一次正经的工程突破,「661%」不是骗术但确实有特定前提,它指向的是「大模型竞赛换赛道」。

一、为什么你的 AI 一直在「挤牙膏」
要理解 DSpark 在解决什么,先得理解一件事:大模型生成慢,不是「算力不够」,是「必须串行」。
主流语言模型是自回归的。第 N+1 个 token,必须等第 N 个算完才能开始。GPU 算一个 token 是几十毫秒量级,要写一段 1000 token 的回复,就是 1000 次串行计算。每多等一个 token,用户都要等几十毫秒。
但这里有个反直觉的物理事实:GPU 解码的瓶颈不是浮点运算,而是显存带宽。
卡帕西讲过一句话:让 GPU 同时解码 10 个 token,其实只比解码 1 个 token 慢一点点。原因在于,模型权重一旦从显存搬到计算核心,搬一次和搬十次的开销差别不大(数据来源:量子位转引卡帕西公开演讲)。既然权重已经在缓存里了,不如一次搬运、干十件事。
这就是推测解码(speculative decoding)的全部物理学基础。

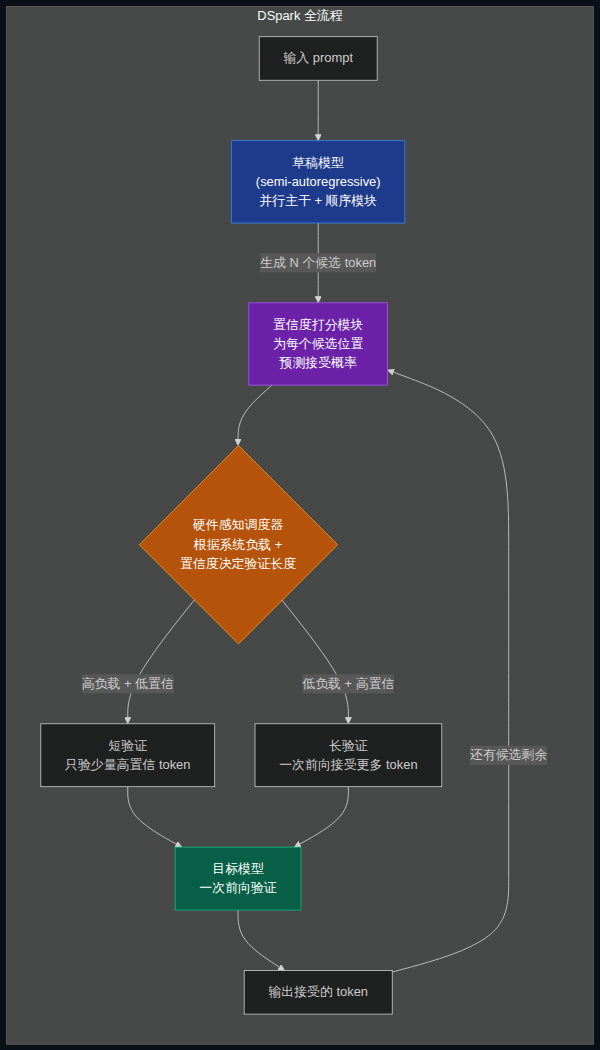
它的思路是:用一个轻量级的「草稿模型」(draft model)先猜出接下来 N 个候选 token,然后让真正负责质量的「目标模型」(target model)一次性批量验证这 N 个 token。验证通过的留下,第一个分歧点之后重新采样。
这样做的好处是:target model 那次贵的前向计算,可以一次性确认多个 token,把多次串行变成一次并行批处理。质量上无任何损失——数学上能证明输出分布和原模型完全一致。
用餐厅类比:自回归是主厨「一道菜做完再做下一道」;推测解码是「让帮厨先把 5 道菜的半成品备好,主厨一次性验收」。
听起来很美。但帮厨备的菜可能不对路。这是 DSpark 要解决的事。
二、老路线的两难:草稿要么慢、要么糊
过去几年推测解码大致走两条路线,两条都有硬伤。
第一条是自回归草稿(Eagle3、MTP)。
草稿模型自己也是一个语言模型,按顺序一个 token 接一个 token 生成候选。好处是前后连贯,候选质量高。但代价是:draft 阶段本身是串行的——你想生成 N 个候选 token,draft 阶段就得跑 N 步。step 数越多,draft 越慢,前面攒下来的批处理优势就被吃光了。
第二条是并行草稿(DFlash)。
借鉴扩散模型的思想,一次前向传播把全部 N 个候选位置同时产出。速度确实快。问题在于各位置之间没有依赖关系。
论文里给了一个直白的例子:模型面对某个上下文,可能同时存在「of course」和「no problem」两种合理续写。位置 1 采出「of」,位置 2 独立采出「problem」,各自看概率都合理,拼在一起就成了「of problem」。论文管这叫多模态碰撞(multimodal collision),更广义的术语是后缀衰减(suffix decay)——位置越靠后,接受率急剧下滑。