DSpark 的 661% 提速,是真突破还是数字游戏?
Site Owner
发布于 2026-07-01
DSpark 的 661% 提速,是真突破还是数字游戏? 2026 年 6 月 27 日,DeepSeek 和北大联合放出论文《DSpark》,梁文锋亲自署名。隔天,爱范儿、量子位接连拆解,标题里都写着两个数字:单用户生成速度提升 85%,高并发场景系统吞吐名义优势 661%。 85% 看起来还行。661% 这个数字太像营销话术了——你买股票一年能涨 661% 吗?一家公司能让推理速度凭空翻 6 ...
DSpark 的 661% 提速,是真突破还是数字游戏?
2026 年 6 月 27 日,DeepSeek 和北大联合放出论文《DSpark》,梁文锋亲自署名。隔天,爱范儿、量子位接连拆解,标题里都写着两个数字:单用户生成速度提升 85%,高并发场景系统吞吐名义优势 661%。
85% 看起来还行。661% 这个数字太像营销话术了——你买股票一年能涨 661% 吗?一家公司能让推理速度凭空翻 6 倍?
这篇论文到底在说什么?这 661% 是怎么算出来的?以及更重要的:DeepSeek 把这套东西开源,意味着大模型竞争进入了什么新阶段?
答案分三层:这是一次正经的工程突破,「661%」不是骗术但确实有特定前提,它指向的是「大模型竞赛换赛道」。

一、为什么你的 AI 一直在「挤牙膏」
要理解 DSpark 在解决什么,先得理解一件事:大模型生成慢,不是「算力不够」,是「必须串行」。
主流语言模型是自回归的。第 N+1 个 token,必须等第 N 个算完才能开始。GPU 算一个 token 是几十毫秒量级,要写一段 1000 token 的回复,就是 1000 次串行计算。每多等一个 token,用户都要等几十毫秒。
但这里有个反直觉的物理事实:GPU 解码的瓶颈不是浮点运算,而是显存带宽。
卡帕西讲过一句话:让 GPU 同时解码 10 个 token,其实只比解码 1 个 token 慢一点点。原因在于,模型权重一旦从显存搬到计算核心,搬一次和搬十次的开销差别不大(数据来源:量子位转引卡帕西公开演讲)。既然权重已经在缓存里了,不如一次搬运、干十件事。
这就是推测解码(speculative decoding)的全部物理学基础。

它的思路是:用一个轻量级的「草稿模型」(draft model)先猜出接下来 N 个候选 token,然后让真正负责质量的「目标模型」(target model)一次性批量验证这 N 个 token。验证通过的留下,第一个分歧点之后重新采样。
这样做的好处是:target model 那次贵的前向计算,可以一次性确认多个 token,把多次串行变成一次并行批处理。质量上无任何损失——数学上能证明输出分布和原模型完全一致。
用餐厅类比:自回归是主厨「一道菜做完再做下一道」;推测解码是「让帮厨先把 5 道菜的半成品备好,主厨一次性验收」。
听起来很美。但帮厨备的菜可能不对路。这是 DSpark 要解决的事。
二、老路线的两难:草稿要么慢、要么糊
过去几年推测解码大致走两条路线,两条都有硬伤。
第一条是自回归草稿(Eagle3、MTP)。
草稿模型自己也是一个语言模型,按顺序一个 token 接一个 token 生成候选。好处是前后连贯,候选质量高。但代价是:draft 阶段本身是串行的——你想生成 N 个候选 token,draft 阶段就得跑 N 步。step 数越多,draft 越慢,前面攒下来的批处理优势就被吃光了。
第二条是并行草稿(DFlash)。
借鉴扩散模型的思想,一次前向传播把全部 N 个候选位置同时产出。速度确实快。问题在于各位置之间没有依赖关系。
论文里给了一个直白的例子:模型面对某个上下文,可能同时存在「of course」和「no problem」两种合理续写。位置 1 采出「of」,位置 2 独立采出「problem」,各自看概率都合理,拼在一起就成了「of problem」。论文管这叫多模态碰撞(multimodal collision),更广义的术语是后缀衰减(suffix decay)——位置越靠后,接受率急剧下滑。
DFlash 在第一个 token 上表现强,因为上下文信息充足;但越往后越糊。「开头精彩、后面崩坏」是并行草稿的真实写照。

更现实的问题发生在线上。数学、代码这些结构化任务,答案路径明确,候选 token 容易被接受;开放式聊天不确定性高,后面的 token 大概率被拒绝。系统空闲时多验证几个 token 没事;系统繁忙时,把那些大概率被拒绝的 token 送给 target model 验证,只会占用批处理容量,拖累其他用户。
换句话说,推测解码的问题已经不只是「能不能一次生成更多 token」,还在于「哪些 token 值得验证」。
三、DSpark 的解法:草稿要像样,审稿要聪明
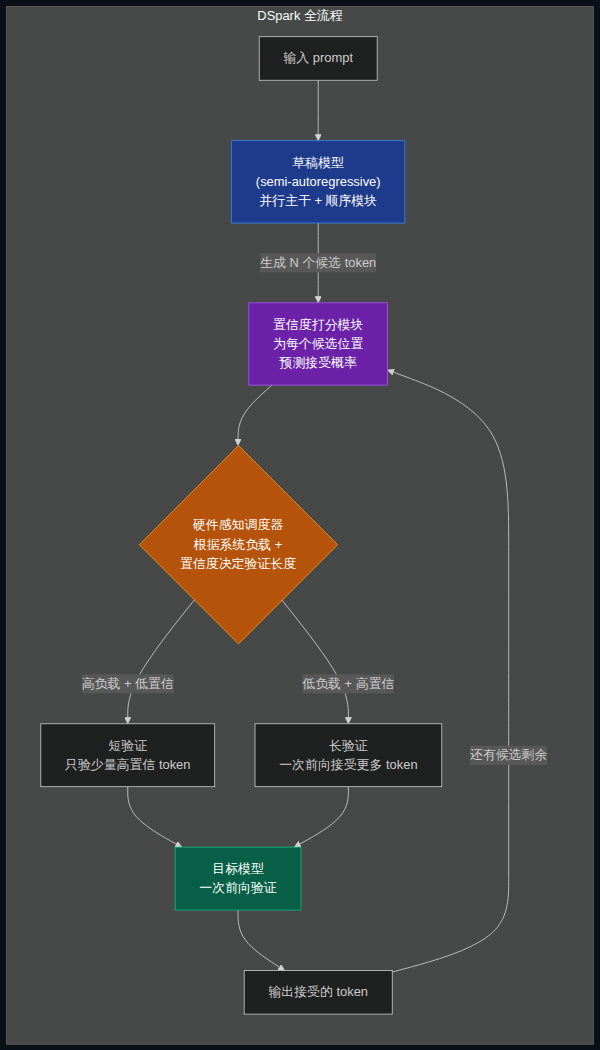
DSpark 的思路可以概括成两件事——草稿要写得更像样,审稿要更会挑重点。
3.1 生成侧:半自回归架构
在草稿这一端,DSpark 采用半自回归(semi-autoregressive)架构。它保留并行草稿的主干,让大部分计算一次完成;同时在输出端加入一个轻量级顺序模块,让后面的 token 能参考前面已经采样出来的 token。
论文默认用 Markov head,只建模相邻 token 之间的转移关系,计算成本低、部署方便;也测试了 RNN head,能保留更长块内历史,但收益有限、复杂度更高。Markov head 是默认方案。
类比一下:帮厨还是并行铺开所有候选(快),但每铺一段,就回头检查相邻两段的衔接(连贯)。
架构实验结果能说明问题:2 层 DSpark 已经超过 5 层 DFlash。意思是,与其把并行层堆得更深,不如加一层轻量级的顺序建模。这对那些已经为 DFlash 堆资源的人是个不小的耳光。
3.2 验证侧:置信度调度的动态决策
这一招才是 DSpark 的杀手锏。
系统会给每个候选位置预测一个 confidence score(置信度分数)。这个分数回答的问题是:在前面的 token 都已经被 target model 接受的情况下,当前位置继续被接受的概率有多高。
然后,hardware-aware prefix scheduler(硬件感知前缀调度器)根据三个因素动态决定每个请求该验证多少 token:
- 当前系统负载
- 每个候选位置的置信度
- 引擎在不同 batch size 下的吞吐曲线
系统资源宽松时,DSpark 可以验证更长的前缀,让一次前向计算尽量产出更多有效 token。系统负载升高时,它会缩短低置信度请求的验证长度,减少对 batch capacity 的占用。
这是和老方案最本质的区别。传统推测解码是「机械地验证固定长度的候选块」。DSpark 不机械——它会根据系统当下的情况,决定这次验证是「多走一步」还是「到此为止」。
3.3 数字:661% 到底怎么来的
论文的离线 benchmark 在 Qwen3-4B/8B/14B 和 Gemma4-12B 上跑,DSpark 相比 Eagle3 的 accepted length(宏平均接受长度)提升 26.7%~30.9%,相比 DFlash 提升 16.3%~18.4%(数据来源:DSpark 论文)。
accepted length 是关键指标,意思是每一轮推测解码中,平均有多少 token 能被 target model 接受。这个数字越高,草稿模型写得越准,加速空间越大。
更有意思的是不同任务的差异。以 Qwen3-4B 为例,数学任务 accepted length 5.57,代码任务 5.12,聊天任务 3.49。结构化任务天然吃这套——答案路径明确,模型容易猜对;开放式聊天不确定性强,模型猜错率高。
所以 DSpark 的置信度调度特别聪明:让系统在结构化任务上「敢验」,在聊天任务上「保守验」。这就是置信度扫表实验的结果——聊天任务 acceptance rate 从 45.7% 提升到 95.7%,数学从 76.9% 到 92.5%,代码从 67.6% 到 92.0%。
然后是线上数据。DeepSeek 在 DeepSeek-V4-Flash preview 和 V4-Pro preview 的生产服务中部署 DSpark,最大 draft 长度设为 5,对比基线是此前的 MTP-1。
- V4-Flash 在 80 token/s/user 服务目标下,DSpark 让系统总吞吐提升 51%。
- 在更严格的 120 token/s/user 目标下,MTP-1 已经接近能力上限,DSpark 给出的名义吞吐优势达到 661%。
这个 661% 怎么理解?不是所有场景都能拿 6 倍提速。更准确的说法是:在高交互、强 SLA 约束下,MTP-1 很难继续维持服务能力,而 DSpark 把原本难以达到的性能区间打开了。
类比一下:你原来开的车最快能到 100 km/h,现在换了发动机,不仅能到 100,还能稳定到 160。在「跑到 120 公里/小时」这个目标下,老发动机的有效功率比是 0,新发动机的有效功率比可以算成无穷大——但这不代表你日常通勤就能跑到 160。661% 是「解锁」的数字,不是「普适提速」的数字。
V4-Pro 的趋势类似。35 token/s/user 目标下总吞吐 +52%,50 token/s/user 严格目标下名义优势 +406%。在相同系统容量下,DSpark 让 V4-Pro 单用户生成速度提升 57%~78%。
到这里,661% 这个数字的真面目就清楚了:它不是吹牛,但有特定前提;它是「高 SLA 场景下的性能解锁」,不是「日常都提速 6 倍」。论文诚实地把基线、目标、batch size 全部列出来,没有回避 MTP-1 已经接近饱和的事实。
四、梁文锋亲自署名,DeepSeek 在押什么
DSpark 这件事最值得关注的不是 661%,是 DeepSeek 的几个动作叠在一起。
第一,梁文锋亲自署名。一篇工程优化论文,老板亲自下场,说明这不是「下面人随便发的成果」,而是公司层面的战略动作。
第二,同步开源 DSpark 模型权重——包括 V4-Flash 和 V4-Pro preview 对应的 DSpark checkpoints。同时开源训练库 DeepSpec,里面包含 Eagle3、DFlash 和 DSpark 三套方案。
第三,Fireworks AI 的 CTO、PyTorch 核心维护者 Dmytro Dzhulgakov 专门撰文拆解 10 个概念,把这篇论文定性为「DeepSeek 这套方案真正的精髓在于系统工程和模型协同设计」(来源:量子位)。
把这三件事拼起来看,信号很明确:
训练更强的模型是牌桌上的硬实力,但能否把模型以更快、更便宜、更稳定的方式送到真实用户面前,同样会决定一款 AI 产品的上限。
OpenAI 把推测解码当「生产细节」藏着,Anthropic 在这方面也相对保守。DeepSeek 选择把这套生产环境里的加速经验开源,等于把一部分真正能提高推理效率、降低服务成本的核心方法,无私分享给全行业。
这背后是一个判断:下一代大模型竞争的牌桌,已经从「谁参数多」换到了「谁推理快」。
中国团队的差异化路径也在浮现——不卷参数上限(这块被 H100/H200 集群规模和 CUDA 生态卡死),卷「同等参数下用户能多快拿到结果」。Kimi 之前用 KVCache 跨地域调度让延迟降 64%,DeepSeek 现在用 DSpark 在单卡层面把单用户速度再提 85%。两条路线指向同一个结论:模型层之上,工程层能榨出的油水比想象中大得多。
大模型竞争的尽头,越来越不是「更大」,而是「更快送到」。
结尾
DSpark 让我重新看 DeepSeek——他们不再只是「开源价格屠夫」,而是中国大模型里第一个把「系统工程」打到战略高度的团队。
论文里那张置信度调度曲线,比任何发布会都更能说明问题:真正的壁垒不在参数表里,在调度器的代码里。
那么问题就剩一个了:OpenAI 什么时候会跟进这套思路?是「技术领先被追平」的不甘,还是「方向根本看不上」的傲慢?
答案可能会在 GPT-5.1 或 Claude 5 的某次更新里揭晓。在那之前,DSpark 至少证明了一件事——大模型竞争的下半场,开源比闭源跑得更快。
参考来源:
- 论文:DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation(DeepSeek × 北大,2026-06-27)。GitHub: https://github.com/deepseek-ai/DeepSpec
- 爱范儿《DeepSeeK 突然发布 DSpark,让 AI 的回答不再「挤牙膏」》:https://www.ifanr.com/1670249
- 量子位《梁文锋署名的 DSpark,看懂这 10 个点就够了!》:https://www.qbitai.com/2026/06/439548.html